编辑:LRS炒股配资最安全平台
【新智元导读】CRATE-α是一种新型Transformer架构变体,通过设计改进提升了模型的可扩展性、性能和可解释性,CRATE-α-Base在ImageNet分类任务上的性能显著超过了之前最好的CRATE-B模型,其性能会随着模型和数据集规模扩大而继续提升。
在过去的几年里,Transformer架构在自然语言处理(NLP)、图像处理和视觉计算领域的深度表征学习中取得了显著的成就,几乎成为了AI领域的主导技术。
然而,虽然Transformer架构及其众多变体在实践中取得了巨大成功,但其设计大多是基于经验的,并没有严格的数学解释,也在一定程度上限制了研究人员的思路,无法开发出更高效、更具可解释性的Transformer新变体。
为了填补这一空白,马毅教授团队曾发布过白盒Transformer模型CRATE,其架构的每一层都是通过数学推导得到的,可以完全解释为展开的梯度下降迭代;此外,CRATE学习到的模型和特征在语义上也比传统的Transformer模型具有更好的可解释性,例如,即使模型仅在分类任务上进行训练,可视化图像的特征也能自然地形成该图像的零样本分割。
然而,到目前为止,CRATE的应用规模仍然相对有限,CRATE-Large只包含77.6M参数,与标准Vision Transformer(ViTs)的22B参数量形成了鲜明对比。
最近,加利福尼亚大学圣克鲁斯分校和伯克利分校的研究团队联合提出了CRATE-α,首次探索了不同规模的CRATE用于视觉任务(从Tiny到Huge)时的模型性能,研究人员在CRATE架构设计中对稀疏编码块进行了策略性但最小化的(strategic yet minimal)修改,并设计了一种轻量级的训练方法,以提高CRATE的可扩展性。

具体来说,CRATE中的ISTA模块是限制进一步扩展的因素,为了克服这一限制,CRATE-α主要做了三个修改:
1. 大幅扩展了通道,对稀疏编码块进行过参数化(overparameterized),使用过完备字典(overcomplete dictionary)对token表征进行稀疏化。
2. 解耦了关联矩阵,在稀疏编码块的最后一部中引入一个解耦字典(decoupled dictionary)
3. 添加了残差连接。
实验结果证明,CRATE-α能够随着模型尺寸和训练数据集的增大而扩展,性能可以持续提升。
例如,CRATE-α-B在ImageNet分类任务上的性能显著超过了之前最好的CRATE-B模型,准确率提高了3.7%,达到了83.2%;进一步对模型进行扩展时,CRATE-α-L在ImageNet分类任务上达到了85.1%的准确率。
值得注意的是,模型性能的提升是在保持甚至增强了CRATE模型可解释性的同时实现的,因为更大尺寸的CRATE-α模型学到的token表征能够生成更高质量的无监督图像分割。
实验结果
从基础尺寸(base)到大尺寸(large)
ImageNet-21K是一个广泛用于图像识别和分类任务的大型数据集,文中用于训练的数据集版本包含19,000个类别和大约1300万张图片,由于数据丢失,比标准数据集(包含21,000个类别和大约1400万张图片)的数据量要少一点。
在预训练时,从数据集中随机选取1%作为验证集。
预训练完成后,在ImageNet-1K数据集上对模型进行微调,其中ImageNet-1K是一个更小的子集,包含1000个类别,通常用于模型的最终评估。在微调阶段,模型会针对这1000个类别进行更精细的训练,以提高其在特定任务上的性能。
最后,在ImageNet-1K的验证集上评估模型的性能。

研究人员对比了在32、16和8像素块大小下的CRATE-α-B和CRATE-α-L,从实验结果中可以看到,CRATE-α-L在所有像素块大小上都取得了显著的改进,但从CRATE-B增加到CRATE-L只能带来0.5%的性能提升,表明了收益递减的情况,证明了CRATE-α模型的可扩展性显著优于普通CRATE
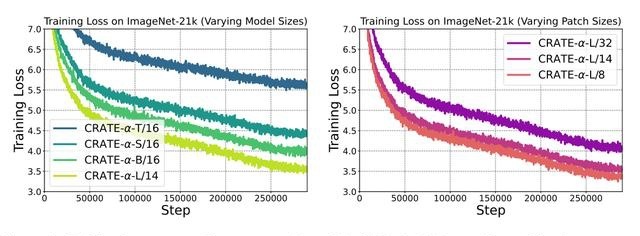
同时,预训练阶段的训练损失显示,随着模型容量的增加,训练损失的趋势可预测地得到改善。
从大(large)到巨大(huge)
多模态数据集DataComp1B包含14亿图文对,可以提供足够的数据来训练和扩展模型。
研究人员采用对比学习的方法来训练CRATE-α,不仅能够利用上庞大的图文对数据集,还能在模型尺寸从大到巨大的提升过程中,观察到显著的性能提升。
然而,直接训练一个类似CLIP的模型需要巨大的计算资源,研究人员采用了优化后的CLIPA协议,可以在减少计算资源消耗的同时,可以保持与CLIP相当的性能。
最后,为了评估CRATE-α模型的性能,研究人员采用了零样本学习的方法,在ImageNet-1K数据集上测试模型的准确率,该方法可以有效地评估模型在面对未见过类别数据时的泛化能力,提供了一个衡量模型可扩展性和实用性的重要指标。
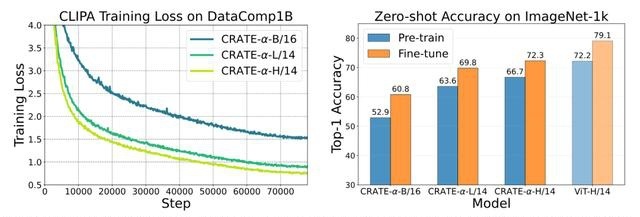
从实验结果中可以看到,
1. 模型尺寸的影响:CRATE-α-CLIPA-L/14在预训练和微调阶段的ImageNet-1K零样本准确率上,分别比CRATE-α-CLIPA-B/16高出11.3%和9.0%,表明学习到的表征质量可能受到模型尺寸的限制,即增加模型尺寸可以利用上更多数据。
2. 扩展模型尺寸的益处:当继续增加模型尺寸时,可以观察到CRATE-α-CLIP-H/14从更大的训练数据集中继续获益,在预训练和微调阶段的ImageNet-1K零样本准确率上,分别比CRATE-α-CLIP-L/14高出3.1%和2.5%,证明了CRATE-α模型的强大可扩展性。
3. 性能上限的探索:为了探索性能的上限,研究人员从头开始训练了一个标准的ViT-CLIPA-H/14,并观察到了性能的提升。
节省计算资源的扩展策略
在追求模型扩展的效率和计算资源的优化方面,研究人员发现,通过调整预训练阶段的图像token序列长度,可以在极大减少计算资源消耗的同时,保持模型性能。
具体来说,研究人员尝试了一种新的方法:在预训练时使用较长序列长度的CRATE-α-L/32,在微调时切换到较短序列长度的CRATE-α-L/14或CRATE-α-L/8,不仅大幅度降低了预训练阶段的计算成本,而且在微调后,模型在ImageNet-1K数据集上的准确率仍然非常接近全尺寸模型的性能。
例如,使用CRATE-α-L/32进行预训练,然后微调到CRATE-α-L/14,可以节省约70%的计算资源,而准确率只是略有下降;更进一步,当从CRATE-α-L/32预训练后微调到CRATE-α-L/8时,仅使用了原模型所需训练时间的10%,准确率依然达到了84.2%,与全尺寸模型的85.1%相差无几。
上述结果表明,通过精心设计预训练和微调阶段的策略,可以在资源有限的情况下,有效地扩展CRATE-α模型。
CRATE-α的语义可解释性得到提升
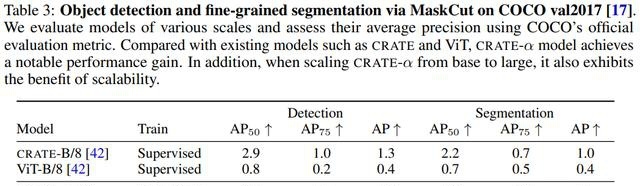
除了可扩展性,文中还研究了不同模型大小的CRATE-α的可解释性,使用MaskCut来验证和评估模型捕获的丰富语义信息,包括定性和定量结果。

为CRATE-α、CRATE和ViT在COCO val2017上提供了分割可视化后,可以发现,CRATE-α模型保持甚至提高了CRATE的(语义)可解释性优势。
业内人士介绍,FDA在CRL中详细说明可能存有的缺陷和风险,并提出建议方案,如果申请人能在规定时间内完成更改,CRL实际上并不影响最终批准。也就是说,此次恒瑞卡瑞利珠单抗的美国上市程序延迟了。恒瑞医药表示,公司计划积极与FDA保持密切沟通,并尽快重新提交上市申请,以期产品能够尽快在美国获批上市。
在COCO val2017上的定量评估结果显示炒股配资最安全平台,当为CRATE-α扩展模型大小时,大型模型在目标检测和分割方面比base模型有所提高。